-- 제약조건 삭제하기
alter table emp07
drop primary key;
alter table emp07
drop constraint emp07_empno_pk;
foreign key : 두개의 테이블을 사용하여 값을 참조하고 제한 하는 조건
-- foreign key (fk)
-- 자식테이블이 부모테이블의 정보를 참조
-- 부모테이블이 먼저 존재
-- 나중에 생성된 테이블이 자식테이블
-- 자식테이블에만 F.K 조건을 설정
-- 부모쪽 해당 컬럼은 primary key여야 한다.
-- fk references 라고 써야한다
-- 컬럼레벨 방식
create table emp08 (
empno number(4) constraint emp08_empno_pk primary key,
ename varchar2(10) constraint emp08_ename_nn not null,
job varchar2(15),
deptno number(2) constraint emp08_deptno_fk references dept(deptno)
);
insert into emp08
values (1111, 'hong', 'sales', 10);
insert into emp08
values (2222, 'kim', 'sales', 50);
select * from emp08;
-- scott 계정은 맥에서 직접 터미널을 이용해 만들었기 때문인지 테이블 정보들이 조금씩 다름
-- dept 테이블 deptno에 pk 설정이 되지 않아 이 구문을 통해 직접 부여
alter table dept
add primary key(deptno);
-- 테이블 레벨 방식
create table emp09 (
empno number(4) constraint emp09_empno_pk primary key,
ename varchar2(10) constraint emp09_ename_nn not null,
job varchar2(15),
deptno number(2),
-- 나의 정보()에 대해 제약조건을 걸겠다 라고 써줘야 한다
constraint emp09_deptno_fk foreign key(deptno) references dept(deptno)
);
-- 테이블이 생성된 후의 레퍼런스(참조)
-- alter table emp09
-- add constraint emp09_deptno_fk foreign key(deptno) references dept(deptno)
실제 프로그램을 짜면 관리해야 하는 데이터가 많은데
여러개의 테이블 중 서로 관계를 맺는 테이블 존재
foreign key 제약조건 성립한 테이블끼리는 조인 조건.
🍀 view
-- view (select 구문이다)
-- 특정 조건에 따라 필터링된 가상 테이블
-- 데이터 보호와 보안을 위해 만들어짐
-- 복잡한 쿼리문의 사용을 단순화할 수 있다
-- crud 가능
-- 뷰 테이블 만드는 형식
create [or replace] view 뷰 이름[(값1, 값2, ... )]
as
서브쿼리문
[with check option]
[with read only]
-- 서브쿼리문
-- select (select)
-- from (select)
-- where (select)
뷰 테이블 만들기에 앞서 원본 테이블이 있어야 함.
-- 원본테이블 생성
create table dept_copy
as
select * from dept;
create table emp_copy
as
select * from emp;
select * from emp_copy;
뷰 테이블 만들기
-- 뷰 테이블 작성
create view emp_view30
as
select * from emp_copy
where deptno = 30;
select * from emp_view30;
테이블을 만드는 것도 권한, (오라클에서 자체적으로 줌)
뷰를 만드는 권한 부여를 해야 함. (system 계정에서 객체 권한 주기)
-- system 계정에서
grant create view
to scott;
(다시 scott계정에서)
뷰 테이블 생성, 삭제, 수정
-- USER_VIEWS
-- 딕셔너리 테이블
-- 구조 보기
desc user_views;
-- 아래 text를 통해 select 구문을 확인할 수 있음
select view_name, text
from user_views;
-- 내꺼 + 위임 받은 view 까지 조회
select view_name, text
from all_views;
create view emp_dept_sal
as
select ename, sal, e.deptno, dname, grade
from emp e inner join dept d
on e.deptno = d.deptno
inner join salgrade s
on e.sal between s.losal and s.hisal;
select * from emp_dept_sal;
-- 뷰 삭제
drop view emp_dept_sal;
-- 뷰 수정
create or replace view emp_view30
as
select empno, ename, sal, hiredate, deptno
from emp_copy
where deptno = 30;
select * from emp_view30;
제약이 있는 뷰 테이블
-- [with check option]
-- 특정 컬럼 정보 수정 불가
-- [with read only]
-- 전체 컬럼 수정 불가
-- 특정 컬럼 정보 수정 불가 뷰
create or replace view view_chk30
as
select empno, ename, sal, comm, deptno
from emp_copy
where deptno = 30 with check option;
select * from view_chk30;
update view_chk30
set deptno = 20 -- 뷰의 WITH CHECK OPTION의 조건에 위배 됩니다
where deptno = 30;
-- 읽기 전용 뷰 (전체 컬럼 수정 불가)
create or replace view view_read20
as
select empno, ename, sal, comm, deptno
from emp_copy
where deptno = 20 with read only;
select * from view_read20;
update view_read20 -- 읽기 전용 뷰에서는 DML 작업을 수행할 수 없습니다.
set sal = sal * 1.1
where sal >= 3000;
뷰 테이블 별칭 부여
-- 별칭 부여 가능 (한글도 가능, 하지만 권하지 않음)
-- 가능하다면 별칭을 안쓰는 것이 좋다
create or replace view view_read10 (사원번호, 사원명, 급여, 부서번호)
as
select empno, ename, sal, deptno
from emp_copy
where deptno = 10 with read only;
select * from view_read10;
select * from view_read10
where ename = 'KING'; -- 오류가 생긴다
-- 뷰테이블을 만들 때 별칭을 부여했다면 조회할 때도 별칭을 사용해야 한다.
select * from view_read10
where 사원명 = 'KING';
뷰 테이블 활용
-- 뷰 테이블을 활용한 TOP-N 구하기
-- rownum(의사컬럼) : 조회 시 레코드 순서대로 1번 부터 번호 부여
-- 오라클 시스템에서 제공해주는 컬럼, 테이블에는 없지만 제공 -> 의사컬럼
-- 아무 테이블이나 사용 가능
-- rownum은 order by절보다 먼저 실행된다, 조건절에 사용 시 반드시 1을 포함한 조건식을 만들어야 한다.
select rownum, empno, ename, sal, deptno
from emp
where rownum >= 1 and rownum <= 2;
-- rownum을 쓰는 순간 * 사용 불가
-- 전체 컬럼 조회 시 테이블에 별칭을 준다
select rownum, e.*
from emp e;
-- 입사일이 가장 빠른 사람 5명
select rownum, e.*
from emp e
order by hiredate asc;
-- order by를 쓰면 rownum 이 섞여버린다
-- order by가 쿼리문의 가장 마지막에 실행됨.
-- 원하는 실행방법이 아님
select rownum, e.*
from emp e
where rownum >= 1 and rownum <= 5
order by hiredate asc;
-- 원하는 형태로 출력을 위해 뷰 테이블 만들어서 출력
create or replace view view_hire
as
select * from emp
order by hiredate asc;
select rownum, h.*
from view_hire h;
select rownum, h.*
from view_hire h
where rownum between 1 and 5;
-- 입사일이 빠른 사람 2번째 ~ 6번째
-- rownum을 간접적으로 사용하기
select rownum, h.*
from view_hire h
where rownum > 1 and rownum <= 6;
-- 실행 X
delete from emp
where ename = 'a';
-- 인라인 뷰
-- 일회성 가상 테이블
-- 메모리의 부화를 주지 않음 -> 효율성이 높아진다
select rownum, h.*
from (
select empno, ename, hiredate
from emp
order by hiredate
) h
where rownum between 1 and 5;
-- 입사일이 빠른 사람 2번째 ~ 6번째
-- rownum에 별칭을 부여함으로서 고정시킬 수 있음.
select rownum rm, h.*
from (
select empno, ename, hiredate
from emp
order by hiredate
) h;
select rm, h2.*
from (
select rownum rm, h.*
from (
select empno, ename, hiredate
from emp
order by hiredate
) h
) h2
where rm between 2 and 6;
→ 게시판 만들기할때 사용
오후에 자바스크립트를 제이쿼리로 바꾸기 시험을 본다.
그 전에 참고할 내용 정리!
$("셀렉터").html()
셀렉터 태그 내에 존재하는 자식태그을 통째로 읽어올때 사용되는 함수
※ 태그 동적추가할때 주로 사용되는 함수
$("셀렉터").text()
셀렉터 태그 내에 존재하는 자식태그들 중에 html태그는 모두 제외 한 채 문자열만 출력하고자 할때 사용되는 함수
※ html태그까지 모두 문자로 인식시켜주는 함수
-- 테이블 만드는 방식 알아보기
-- DDL (data definition language)
-- creat : 객체 생성
-- alter : 객체 수정
-- drop : 객체 삭제
-- truncate : 테이블을 초기화 (전체 데이터 삭제)
-- create table 테이블명 (
-- 컬럼명1 타입,
-- 컬럼명2 타입,
-- 컬럼명3 타입,
-- );
-- 컬럼이름을 만든 후 타입에 사용
-- 숫자 : number(4), number(7,2)
-- 문자 : char(10) : 고정형, varchar2(10) : 가변형
-- 문자를 다룰 때는 가변형을 주로 사용한다
-- 날짜 : date, timestamp
-- 큰 데이터를 담을 때 : lob, blob
-- 테이블명, 객체이름
-- 공백, 특수문자, 예약어 안됨
테이블을 만드는 방식 두 가지
직접 만들기
서브쿼리문을 사용한 테이블 생성
서브쿼리문을 사용해 테이블 만들기
-- 서브쿼리문을 사용한 테이블 생성 (테이블 복사)
-- 테스트용, 백업용으로 주로 만든다
create table emp02
as
select * from emp;
desc emp02;
select * from emp02;
create table emp03
as
select empno, ename from emp;
create table emp04
as
select * from emp
where deptno = 30;
desc emp04;
select * from emp04;
-- 구조만 복사
create table emp05
as
select * from emp
where 1 = 0;
select * from emp05;
객체 수정
-- alter : 객체 수정
-- 테이블을 대상으로 컬럼을 수정 (add, modify, drop)
desc emp01;
alter table emp01
add (job varchar2(9));
desc emp01;
-- modify
-- 해당 컬럼의 크기나 타입 수정
-- 기존 데이터에 문제가 되지 않는 선에서 수정해야 한다
alter table emp01
modify (job varchar(30));
desc emp01;
객체 삭제
-- 삭제
alter table emp01
drop column job;
desc emp01;
select * from tab;
drop table emp01;
삭제를 해도 임시로 휴지통에 보관을 해서 다시 사용할 수 있다!
🗑 휴지통에서 데이터 가져오기, 비우기
-- 휴지통 정보를 확인
show recyclebin;
-- 휴지통에서 원래 위치로 가져다 놓기
flashback table emp01
to before drop;
-- 휴지통 비우기
-- 이걸하면 원복할 방법이 없다
purge recyclebin;
🗑휴지통에 넣지 않고 데이터 완전 삭제
-- 데이터 완전 삭제
select * from emp02;
truncate table emp02;
🍀 딕셔너리 (데이터 사전)
-- 이런 모든 작업을 다 저장, 관리해주는 오라클DB
-- 딕셔너리 (데이터 사전)
-- 오라클DB가 자체적으로 관리하는 테이블.
-- 사용자가 직접 접근하지 못한다
-- 권한 별 접근 제한
-- XXX : 대상 객체를 의미 (table, index, veiw ...)
-- DBA_XXX (DBA 계정만) (system 계정도 DBA)
-- ALL_XXX (해당 계정의 객체 + 위임받은 정보)
-- USER_XXX (해당 계정의 객체)
select * from dict
where table_name like '%USER_TABLE%';
desc user_tables;
select table_name
from user_tables;
desc all_tables;
-- 위임받은 테이블 조회
select owner, table_name
from all_tables;
🍀 DML
-- DML (Data Manipulation Language)
-- 테이블에 데이터 조작
-- insert : 데이터 삽입
-- update : 데이터 수정
-- delete : 데이터 삭제
insert : 데이터 삽입
-- insert
-- 1. 컬럼의 개수가 값의 개수와 일치해야 한다
-- 2. 값의 타입도 일치해야 한다.
insert into 테이블명 (컬럼명1, 컬럼명2, 컬럼명3, ... )
values (값1, 값2, 값3, ... )
desc dept01;
insert into dept01 (deptno, dname, loc) -- 자동형변환
values (10, 'sales' , 'inchon');
-- insert into dept01 (deptno, dname, loc)
-- values ('aaa', 'sales' , 'inchon'); -- 자동형변환 불가
insert into dept01 (deptno, dname, loc) -- 자동형변환
values (10, 'sales' , 300); -- 숫자를 문자로 묶어도 문제가 되지 않아 자동형변환이 일어남
insert into dept01 (deptno, dname) -- 묵시적 null 삽입
values (20, 'sales');
insert into dept01 (deptno, dname, loc) -- 명시적 null 삽입
values (10, 'sales' , null);
insert into dept01 -- 컬럼을 생략하면 반드시 모든 컬럼에 값을 정의해야 한다
values (30, 'sales' , 'seoul');
select * from dept01;
오 이거 이제 보니 어제 oe 계정 만들면서 빡세게 했던거다!
역시 프로그래밍은 해매도 길이다 !
update : 데이터 수정
-- update
-- update 테이블명
set 컬럼명1 = 값1, 컬럼명2 = 값2, 컬럼명3 = 값3, ...
[where 조건식];
drop table emp01;
create table emp01
as
select * from emp;
update emp01
set deptno = 30;
update emp01
set empno = 1111, job = 'SALESMAN';
update emp01
set sal = sal * 1.1
where sal >= 3000;
select * from emp01;
-- 83년에 입사한 사원을 오늘 날짜로 수정
update emp01
set hiredate = sysdate
where substr(hiredate,1,2) = '83';
select * from emp01;
select ename, hiredate
from emp
where substr(hiredate,1,2) = '83';
delete : 데이터 삭제
-- delete
delete from 테이블명
[where 조건식]
delete from dept01
where deptno = 20;
select * from dept01;
🍀 트랜잭션
DML를 이용해 작업한 후에는 트랜잭션를 이용해 테이블에 반영하는 작업을 해줘야 한다. 그렇지 않으면 반영되지 않는다.
-- DML를 이용해 작업한 후에는 트랜잭션를 이용해 테이블에 반영하는 작업을 해줘야 한다.
-- 트랜잭션
-- TCL
-- commit : 해당테이블에 작업한 내용을 반영
-- rollback : 해당테이블에 작업한 내용을 반영하지 않는다. (작업 이전 상태로 원복)
-- rollback을 하면 이전 commit 위치로 돌아간다.
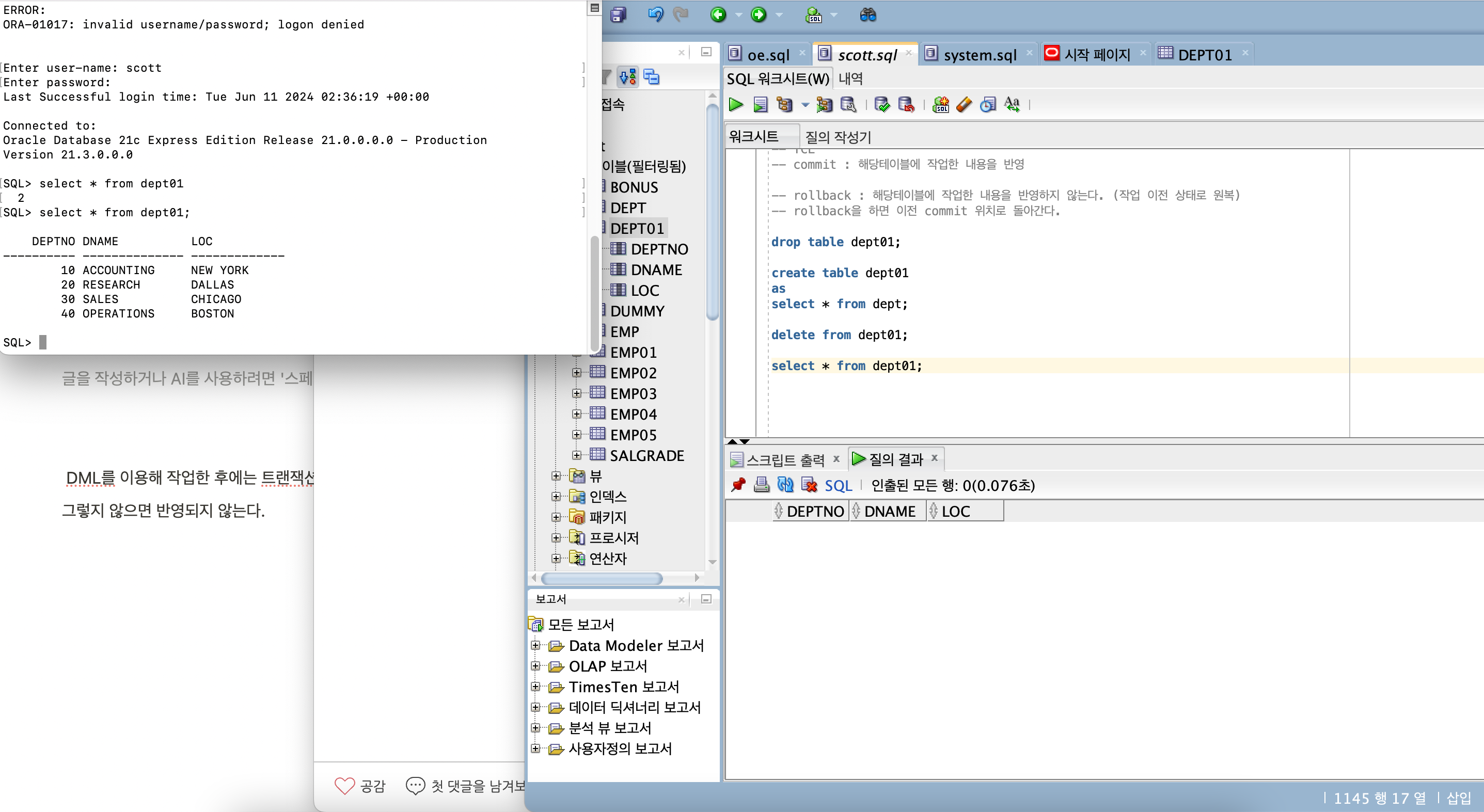
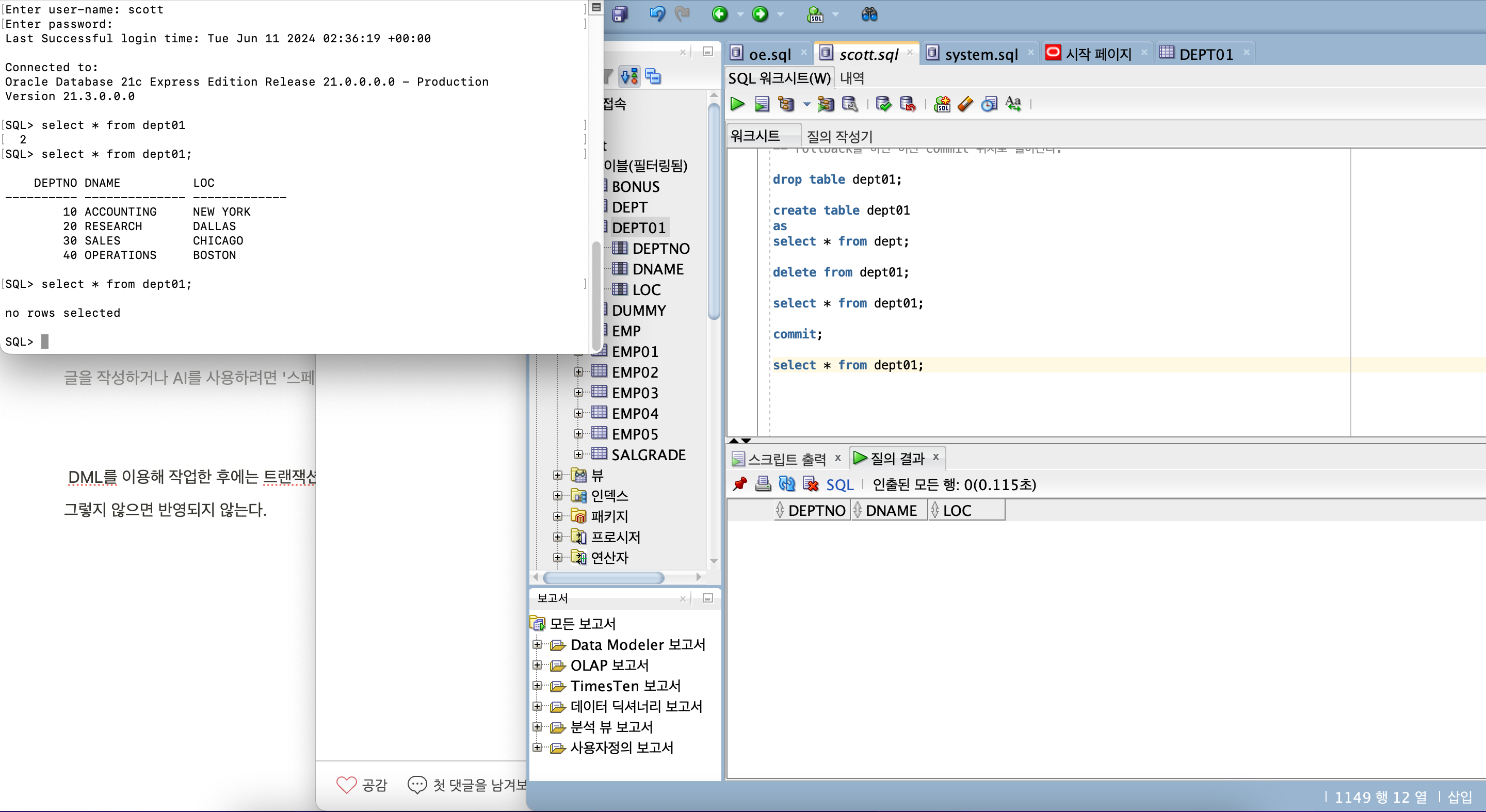
drop table dept01;
create table dept01
as
select * from dept;
delete from dept01;
commit;
delete from dept01;
rollback;
select * from dept01;
-- delete (tx 가능), truncate (tx 불가)
commit 을 해야 실질적으로 반영된다.
테이블 생성 시 5대 제약조건
-- 5대 제약조건 : 무결성 데이터 처리
-- 무결성 -> 원하지 않는 데이터
-- 컬럼의 값을 제약
-- not null : null를 허용하지 않는다.
-- unique : 중복된 값을 허용하지 않는다.
-- primary key : not null + unique
-- check : 값의 범위를 제한
-- foreign key : 두개의 테이블을 사용하여 값을 참조하고 제한 하는 조건
-- 제약조건을 주는 방식 3가지
-- 컬럼레벨 방식 : 컬럼을 정의하면서 제약조건을 정의하는 방식
-- 테이블 레벨 방식 : 컬럼의 정의와 제약조건 정의를 따로 분리하는 방식
-- 1. 테이블 안에서 제약 조건을 분리하는 방식
-- 2. 테이블 밖으로 제약 조건을 분리하는 방식
desc user_constraints;
select CONSTRAINT_NAME,CONSTRAINT_TYPE,TABLE_NAME
from user_constraints;
p : pk
r : fk
u : uk
c : ck,not null
select CONSTRAINT_NAME,CONSTRAINT_TYPE,TABLE_NAME
from user_constraints;
select *
from user_cons_columns;
not null , unique
-- not null 과 unique
drop table emp01;
create table emp01(
empno number(4) not null,
ename varchar2(10) not null,
job varchar2(10)
);
insert into emp01 (empno,ename,job)
values (1111,'hong','SALES');
select * from emp01;
drop table emp02;
create table emp02(
empno number(4) unique not null,
ename varchar2(10) not null,
job varchar2(10)
);
insert into emp02
values (1111,'hong','sales');
insert into emp02
values (1111,'kim','dev'); -- 같은 값 중복
insert into emp02
values (null,'park','dev'); -- null 삽입 불가
insert into emp02
values (null,'cho','dev');
select * from emp02;
primary key
-- primary key
drop table emp03;
create table emp03 (
empno number(4) primary key,
ename varchar2(10) not null,
job varchar2(10)
)
insert into emp03
values (1111, 'hong', 'sales');
insert into emp03
values (null, 'hong', 'sales'); -- null을 삽입할 수 없다
select * from emp03;
check
-- check
drop table emp04;
create table emp04 (
empno number(4) primary key,
ename varchar2(10) not null,
sal number(7,2) check(sal between 500 and 5000),
gender varchar2(2) check(gender in ('M','F'))
);
insert into emp04
values (1111, 'hong', 1000, 'F');
insert into emp04
values (2222, 'kim', 100, 'F'); -- 체크 제약조건 위배
insert into emp04
values (3333, 'kang', 1000, 'A'); -- 체크 제약조건 위배
select * from emp04;
제약조건명 지정
-- 제약조건명을 직접 지정할 수도 있다.
-- 제약조건명은 유니크해야 한다.
drop table emp05;
create table emp05 (
empno number(4) constraint emp05_empno_pk primary key,
ename varchar2(10) constraint emp05_ename_nn not null,
sal number(7,2) constraint emp05_sal_ck check(sal between 2000 and 5000),
gender varchar2(2) constraint emp05_gender_ck check(gender in ('M','F'))
);
insert into emp05
values (1111, 'kang', 2000, 'F');
insert into emp05
values (1111, 'kim', 2000, 'F'); -- 체크 제약조건 위배
insert into emp05
values (2222, 'hong', 100, 'F'); -- 체크 제약조건 위배
insert into emp05
values (2222, 'hong', 100, 'A'); -- 체크 제약조건 위배
select * from emp05;
-- 값을 디폴트하게 제어하는 방식
drop table dept01;
create table dept01 (
deptno number(2) primary key,
dname varchar2(10) not null,
loc varchar2(10) default 'SEOUL'
);
insert into dept01 (deptno, dname)
values (10, 'DEV');
insert into dept01 (deptno, dname, loc)
values (20, 'DEV', 'BUSAN');
select * from dept01;
위에는 다 컬럼레벨 방식으로 제약조건을 줬다.
제약조건을 주는 방식 - 테이블 레벨
-- 테이블 레벨 방식의 재약 조건 설정하기
-- not null 제약조건은 컬럼 레벨 방식만 가능
create table emp06 (
empno number(4),
ename varchar2(10) constraint emp06_ename_nn not null,
job varchar2(10),
deptno number(2),
constraint emp06_empno_pk primary key (empno),
constraint emp06_job_uk unique(job)
);
select CONSTRAINT_NAME,CONSTRAINT_TYPE,TABLE_NAME
from user_constraints
where table_name = 'EMP06';
select *
from user_cons_columns
where table_name = 'EMP06';
-- 외부에서 제약조건을 주는 방식
-- 테이블 생성
create table emp07 (
empno number(4),
ename varchar2(10),
job varchar2(10),
deptno number(2)
);
-- 테이블 생성 후 제약조건을 분리해서 주기
-- alter table 테이블명
-- add 제약조건명 제약조건(컬럼명)
alter table emp07
add constraint emp07_empno_pk primary key(empno);
alter table emp07
add constraint emp07_job_uk unique(job);
-- null 값을 줄 수는 없지만 null로 상태를 변경할 수 있다
alter table emp07
modify ename constraint emp07_ename_nn not null;
select CONSTRAINT_NAME,CONSTRAINT_TYPE,TABLE_NAME
from user_constraints
where table_name = 'EMP07';
select *
from user_cons_columns
where table_name = 'EMP07';
나이 구하기
+ 연령대 구하기
select date_of_birth,to_char(date_of_birth,'YYYY/MM/DD') as birth,
trunc((sysdate - date_of_birth) / 365) as age,
case
when trunc((sysdate - date_of_birth) / 365) >= 70 and trunc((sysdate - date_of_birth) / 365) < 80 then '70대'
when trunc((sysdate - date_of_birth) / 365) >= 60 and trunc((sysdate - date_of_birth) / 365) < 70 then '60대'
when trunc((sysdate - date_of_birth) / 365) >= 50 and trunc((sysdate - date_of_birth) / 365) < 60 then '50대'
when trunc((sysdate - date_of_birth) / 365) >= 40 and trunc((sysdate - date_of_birth) / 365) < 50 then '40대'
when trunc((sysdate - date_of_birth) / 365) >= 30 and trunc((sysdate - date_of_birth) / 365) < 40 then '30대'
when trunc((sysdate - date_of_birth) / 365) >= 20 and trunc((sysdate - date_of_birth) / 365) < 30 then '20대'
when trunc((sysdate - date_of_birth) / 365) >= 10 and trunc((sysdate - date_of_birth) / 365) < 20 then '10대'
else '기타'
end as Generation
from customers;
---------------------------------------------------------------------------------------------------
위 구문을 식으로 바꿔보았다 (아래)
select date_of_birth,to_char(date_of_birth,'YYYY/MM/DD') as birth,
trunc((sysdate - date_of_birth) / 365) as age,
case
when sysdate-date_of_birth >= 0 then floor(floor((sysdate-date_of_birth)/365)/10)*10 || '대'
else '기타'
end as Generation
from customers;
조건이 반복되면 간략하게 만들어서 사용할 생각을 하자
다시 scott 계정으로 돌아왔다
단일행 함수 → input과 output의 수가 같음.
다중행 함수 → input이 여러개여도 output은 하나
-- 단일행 합수 : round(), floor()..
-- 다중행 함수 : sum(), avg(), max(), min(), count()..
-- 회사직원들의 급여 합, 평균
-- distinct 중복제거
select sum(sal), sum(distinct sal), avg(distinct sal)
from emp;
select sal
from emp;
-- 전체 사원 14명, 성과금받는 직원 4명, 성과금의 합 2200, 급여가 같은 사원 중복제거
-- 다중행함수는 null 값을 무시한다
select count(*), count(comm), sum(comm), count(distinct sal)
from emp;
select max(sal), min(sal)
from emp;
-- 일반컬럼과 단일행 그룹 함수는 함께 사용할 수 없다.
-- 각 컬럼에 조회된 결과의 개수가 같아야 한다.
select ename, max(sal)
from emp;
-- 일반컬럼과 단일행 그룹 함수는 함께 사용할 수 없다.
select max(sal)
from emp;
-- 추후 해결하는 방법을 배울 예정
group by절
-- group by 기준 컬럼
-- 테이블에 데이터를 논리적으로 묶어서 처리하는 역할
select *
from emp
order by deptno;
-- 부서 별 급여의 합계, 평균
-- group by로 묶이면 그룹의 갯수대로 값이 나온다
-- group by에 사용되는 컬럼은 그룹함수와 함께 사용될 수 있다
select deptno, sum(sal), avg(sal)
from emp
group by deptno;
select *
from emp
order by deptno;
select deptno, job, sum(sal)
from emp
group by deptno, job
order by deptno;
-- having 조건절
-- where 그룹함수를 조건식으로 사용 불가, group by절 보다 먼저 실행된다
select deptno, sum(sal)
from emp
group by deptno
having sum(sal) > 9000;
-- where절과 group by절을 함께 사용한 예제
select deptno, job, avg(sal)
from emp
where sal <= 3000
group by deptno, job
-- having avg(sal) >= 2000; -- 그룹함수를 사용하여 조건식을 구성한다.
having deptno = 10;
문제풀기
-- 문제 풀기
-- 1번
select deptno, trunc(avg(sal)) as AVG_SAL, max(sal) as MAX_SAL, min(sal) as MIN_SAL, count(*) as CNT
from emp
group by deptno;
-- 2번
select job, count(*)
from emp
group by job
having count(*) >= 3;
-- 3번
select to_char(hiredate,'YYYY') as HIRE_YEAR, deptno, count(*) as CNT
from emp
group by to_char(hiredate,'YYYY'), deptno
order by HIRE_YEAR;
group by 절 사용 방법
select
from
where
group by
having
order by -- 가장 마지막에 작성
join
조인 - 두개 이상의 테이블을 사용하여 데이터를 조회하는 것 - 두개의 테이블의 공통컬럼을 사용하여 데이터를 조회 - 하나의 쿼리문으로 데이터 통합 조회 - from절에 두개 이상의 테이블을 사용한다
--종류 -- cross join : 조건없이 양쪽 테이블을 모두 조회 -- equi join : 공통 컬럼에 값을 비교해서 같으면 조회(등가) -- non equi join : 컬럼의 값을 범위 비교한다 -- self join : 하나의 테이블을 두개의 테이블처럼 사용하여 조회(등가) -- outer join : 누락된 데이터를 조회(등가)
select *
from emp;
select *
from dept;
-- cross join
select *
from emp, dept;
-- equi join
select ename, sal, emp.deptno, dname, loc
from emp, dept
where emp.deptno = dept.deptno; -- 조인 조건
-- 공통으로 가지고 있는 컬럼이 아니라면 생략이 가능하다
-- select emp.ename, emp.sal, emp.deptno, dept.dname, dept.loc
select ename, sal, e.deptno, dname, loc
from emp e, dept d -- 별칭사용 (원래 테이블명 사용불가)
where e.deptno = d.deptno -- 조인 조건
and ename = 'SMITH'; -- 일반 조건
-- non equi join
select *
from emp;
select *
from salgrade;
select ename, sal, grade
from emp e, salgrade s
-- where e.sal >= s.losal and e.sal <= s.hisal; -- 범위 비교
where e.sal between s.losal and s.hisal;
-- slef join
select *
from emp;
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e, emp m -- emp(mgr) = emp(empno)
where e.mgr = m.empno; -- 조인 조건
-- null값 누락
-- outer join
-- 누락되는 null 값도 가지고 온다
-- 조인 조건식의 한쪽 컬럼에 (+)표시를 작성한다 -> 해당 데이터가 없는 쪽에 붙일 것.
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e, emp m -- emp(mgr) = emp(empno)
where e.mgr = m.empno(+); -- 조인 조건
select ename, sal, d.deptno, dname
from emp e,dept d
where e.deptno(+) = d.deptno;
-- 사원이름, 급여, 부서번호, 부서명, 급여등급
select ename, sal, e.deptno, dname, grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal and s.hisal;
표준조인방식
-- 표준 조인 방식 (ANSI-JOIN)
-- 위의 조인 방식은 오라클에서 쓸 수있는 조인
-- 이 표준 조인 방식은 어디에서나 사용 가능
-- 호환성을 위해 표준을 쓰는 것을 권고한다
-- 종류
-- cross join
-- inner join(equi join, non equi join, self join)
-- outer join
select *
from emp cross join dept;
-- 조건문 on
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d -- inner 생략 가능
on e.deptno = d.deptno;
-- 일반조건 추가 where
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d -- inner 생략 가능
on e.deptno = d.deptno -- 조인조건
where ename = 'SCOTT'; -- 일반조건
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d
-- on e.deptno = d.deptno
using(deptno); -- 조인 조건 (컬럼명이 동일할 경우)
select ename, sal, grade
from emp e inner join salgrade s
on e.sal between s.losal and s.hisal;
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e inner join emp m
on e.mgr = m.empno;
-- left, right, full을 outer 앞에 붙여줘야한다
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e left outer join emp m
on e.mgr = m.empno;
-- 테이블 먼저 나열하고 쓰면 안된다
select ename, sal, e.deptno, dname, grade
from emp e inner join dept d
on e.deptno = d.deptno
inner join salgrade s
on e.sal between s.losal and s.hisal;
서브쿼리문
-- 서브 쿼리문
-- select 문 안에 중첩되는 select 구문
-- 단일행 서브쿼리 : 결과가 하나 (비교연산자)
-- 다중행 서브쿼리 : 결과가 여러 개 (비교연산자 사용 불가), in, any, all
-- select (select)
-- from (select)
-- where (select)
--------------------단일행 서브쿼리--------------------
-- SCOTT 보다 급여를 많이 받는 사람을 알고 싶을 때
select sal
from emp
where ename = 'JONES';
select *
from emp
where sal > (
select sal
from emp
where ename = 'SCOTT'
);
-- 근무지가 뉴욕인 사람들
select *
from emp
where deptno = (
select deptno
from dept
where loc = 'NEW YORK'
);
-- 급여를 가장 많이 받는 사원의 급여와 사원이름
select max(sal)
from emp;
select ename,sal
from emp
where sal = (
select max(sal)
from emp
);
--------------------단일행 서브쿼리--------------------
--------------------다중행 서브쿼리--------------------
-- 급여를 3000 이상 받는 사람들
select ename, sal, deptno
from emp
where deptno in ( -- or 조건과 동일
select distinct deptno
from emp
where sal >= 3000
);
-- 30번 부서에서 근무하는 사람들의 급여 조회, 그 급여보다 많은 급여를 받는 사람 조회
select ename, sal
from emp
where sal > all (
select sal
from emp
where deptno = 30
);
-- any : 값 중에 가장 작은 값보다 큰 값을 가진 사원 조회
-- all : 값 중에 가장 큰 값보다 큰 값을 가진 사원 조회
--------------------다중행 서브쿼리--------------------
✔️ 테이블 만들기
DDL (data definition language) -- creat : 객체 생성 -- alter : 객체 수정 -- drop : 객체 삭제 -- truncate : 테이블을 초기화
create table 테이블명 (
컬럼명1 타입,
컬럼명2 타입,
컬럼명3 타입,
);
-- 컬럼이름을 만든 후 타입에 사용
-- 숫자 : number(4), number(7,2)
-- 문자 : char(10) : 고정형, varchar2(10) : 가변형
-- 문자를 다룰 때는 가변형을 주로 사용한다
-- 날짜 : date, timestamp
-- 합집합 (union)
select empno, ename, sal, deptno
from emp
where deptno = 10
union
select empno, ename, sal, deptno
from emp
where deptno = 20;
union → 중복 제거
union all → 중복 허용
-- 차집합 (minus)
select empno, ename, sal, deptno
from emp
minus
select empno, ename, sal, deptno
from emp
where deptno = 10;
-- 교집합
select empno, ename, sal, deptno
from emp
intersect
select empno, ename, sal, deptno
from emp
where deptno = 10
문제풀이) 내가 푼 ver.
-- 문제 1번
-- 이름이 s 로 끝나는 사람
select *
from emp
where ename like '%S';
-- 문제 2번
-- 30번 부서에서 근무하는 사람
select empno, ename, job, sal, deptno
from emp
where deptno = 30;
-- 문제 3번
-- 급여가 2000 초과인 사원
-- 집합연산자 사용 X
select empno, ename, sal, deptno
from emp
where sal > 2000 and (deptno = 20 or deptno = 30);
-- 집합연산자 사용
select empno, ename, sal, deptno
from emp
where sal > 2000
intersect
select empno, ename, sal, deptno
from emp
where deptno = 20 or deptno = 30;
-- 문제 4번
-- 급여 2000 이상 3000 이하 이외의 범위
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
minus
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where sal >= 2000 and sal <= 3000;
-- 문제 5번
-- 이름에 E 포함, 급여 1000 ~ 2000 사이
select empno, ename, sal, deptno
from emp
where ename like '%E%'
and not (sal >= 1000 and sal <= 2000);
-- 문제 6번
-- 추가수당 X , 'MANAGER','CLERK' 직책 구분, 이름의 두번째 글자가 L이 아닌 사원
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where comm is null
intersect
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp
where (job = 'MANAGER' or job = 'CLERK')
and ename not like '_L%';
강사님 ver.
-- 문제 3번
-- 집합연산자 사용 X
select empno, ename, sal, deptno
from emp
where deptno in(20, 30)
and sal > 2000;
-- 문제 5번
-- 이름에 E 포함, 부서 30, 급여 1000 ~ 2000 사이
select empno, ename, sal, deptno
from emp
where ename like '%E%'
and deptno = 30
and sal not between 2000 and 3000;
-- 문제 6번
-- 추가수당 X , 상급자가 없고, 'MANAGER','CLERK' 직책, 이름의 두번째 글자가 L이 아닌 사원
select *
from emp
where comm is null
and mgr is not null
and job in ('MANAGER','CLERK')
and ename not like '_L%';
문제에서 놓친 조건이 있었다.. 문제를 잘 읽자!
그리고 in을 잘 활용해야겠다.
함수
문자함수
숫자함수
날짜함수
🍀 문자함수
-- 문자함수
-- upper 대문자 lower 소문자 initcap 첫글자 대문자 뒤는 소문자
select upper(ename), lower(ename), initcap(ename)
from emp;
select *
from emp
where ename = upper('scott');
select *
from emp
where lower(ename) = 'scott';
-- length 길이
select ename, length(ename)
from emp
where length(ename) >= 5;
-- 문자열에서 일부 추출
-- 오라클DB에서 인덱스는 1번부터 시작
-- substr (문자열, 시작위치, 개수)
-- substr (문자열, 시작위치)
select job, substr(job, 1, 2), substr(job, 5)
from emp;
-- 원하는 문자를 넣어 확인 dual
-- 문자를 변경하고 싶을 때
select '010-123-1234' as phone,
replace('010-123-1234', '-', '/'),
replace('010-123-1234', '-') -- '-'가 빠진다
from dual;
-- 문자연결
select ename || ' is a ' || job
from emp;
select concat(empno, ename)
from emp;
select concat(ename, concat(' is a ', job))
from emp;
-- instr(문자열, 찾고자하는 문자)
-- instr(문자열, 찾고자하는 문자, 문자를 찾고자하는 시작위치)
-- instr(문자열, 찾고자하는 문자, 문자를 찾고자하는 시작위치, 찾으려는 문자가 몇번째 있는 문자인지(위치))
select instr('HELLO, ORACLE','L'),
instr('HELLO, ORACLE','L', 5),
instr('HELLO, ORACLE','L', 2, 2)
from dual;
-- 문제
-- 1번. 입사일자 82년도 입사한 사람 조회
select *
from emp
where hiredate between '19820101' and '19821231';
-- substr() 이용
select *
from emp
where substr(hiredate, 1, 2) = '82';
-- 2번. 이름에 세번째 문자가 R인 사원 조회
select *
from emp
where ename like '__R%';
-- substr() 이용 -> 문자반환
select *
from emp
where substr(ename, 3, 1) = 'R';
-- instr() 이용 -> 위치반환
select *
from emp
where instr(ename,'R', 3, 1) = 3;
🍀 숫자함수
-- 숫자함수
-- 소수점(실수) 다루는 함수가 대부분
-- round() : 반올림
-- trunc() : 실수를 버림
-- ceil() : 강제 올림
-- floor() : 강제 내림
-- mod() : 나머지 구하기
-- round()
select
round(1234.5678),
round(1234.5678,1),
round(1234.5678,2)
from dual;
-- trunc()
select
trunc(1234.5678),
trunc(1234.5678, 1),
trunc(1234.5678, 2)
from dual;
-- ceil(), floor()
select
ceil(3.14),
floor(3.14)
from dual;
-- mod() 나머지
select
mod(15,6),
mod(11,2)
from dual;
-- 사원 중에 사번이 홀수인 사원
select *
from emp
where mod (empno,2) = 1;
🍀 날짜함수
-- 날짜함수
-- 연산이 가능
-- 현재 날짜 정보
select sysdate
from dual;
select sysdate - 1 as "어제",sysdate, sysdate + 1 as "내일"
from dual;
-- 날짜 데이터끼리 연산 가능
select trunc(sysdate - hiredate) as "근무일수", trunc((sysdate - hiredate)/365) as "근무년수"
from emp;
-- 달을 기준으로 연산
select sysdate, add_months(sysdate, 3)
from dual;
-- 문제
-- 근속 년수가 41년 이하인 사원 조회
select *
from emp
where trunc((sysdate - hiredate)/365) <= 41;
-- add_months()
select *
from emp
where add_months(hiredate, 12 * 43) <= sysdate;
✨ 형변환
-- 형변환
-- to_number(), to_char(), to_date()
-- 숫자 -> 문자 -> 날짜
-- <- <-
-- 날짜를 문자로
select sysdate, to_char(sysdate, 'YYYY/MM/DD DY HH:MI:SS')
from dual;
-- 숫자를 문자로
-- 0, 9
-- L 로컬(지역) 돈 단위로 처리
select sal, to_char(sal,'L9,999')
from emp;
-- 문자를 숫자로
select '1300' - '1000' -- 자동형변환
from dual;
select to_number('1,300', '9,999') - to_number('1,000', '9,999')
from dual;
-- 문자를 날짜로
select to_date('2024-01-01','YYYY-MM_DD')
from dual;
select *
from emp
where hiredate >= '1981/01/01'; -- to_date('1981/01/01','YYYY/MM/DD');ㅍ
-- 기타함수
-- nvl()
-- 조건문 형식 함수
-- decode(값, 비교값1, 결과1, 비교값2, 결과2, 비교값3, 결과3, 기타결과)
-- 비교값1, 결과1 -> 한쌍
-- 비교했을때 원하는 값이 없으면 기타결과가 출력
-- -> switch case 문과 유사하다
-- case 구문 -> 다중 if 문과 유사
select deptno,
decode(deptno,
10, 'ACCOUNTING',
20, 'RESEARCH',
30, 'SALES',
40, 'OFERATIONS',
'ETC'
)
from emp;
-- JOB이 manage인 사원의 급여를 10% 인상한 결과를 출력
-- JOB이 salesman 사원 급여를 5% 인상한 결과 출력
-- JOB이 analyst 사원은 급여를 동결한 결과 출력
-- 기타 JOB인 사원들은 3% 급여 인상
select job, sal,
decode(job,
'MANAGER', sal * 1.1,
'SALESMAN', sal * 1.05,
'ANALYST', sal,
sal * 1.03
)
from emp;
select job, sal,
case job
when 'MANAGER' then sal * 1.1
when 'SALESMAN' then sal * 1.05
when 'ANALYST' then sal
else sal * 1.03
end as upsal
from emp;
-- 범위비교
select job, sal,
case
when sal >= 3000 and sal <= 5000 then sal * 1.1
when sal >= 2000 and sal < 3000 then sal * 1.05
when sal >= 1000 and sal < 2000 then sal
else sal * 1.03
end as upsal
from emp;
맥에서 계정 풀어서 만들어야함.
oe계정 만들기
select date_of_birth, to_char(date_of_birth, 'YYYY-MM-DD') as birth
from customers;
oe.sql → 오라클에서 지원해주는 교육용 DB
------> 어떻게 해도 안돼서 그냥 노가다로 하나씩 집어넣었다; 자세한 내용은 아래 참조.
select deptno, dname, loc
from dept;
select empno, ename, job, mgr, hiredate, sal, comm, deptno
from emp;
-- * : 모든 컬럼을 조회할 때
select *
from emp;
select empno, ename, job
from emp;
select문을 사용하는 이유 : 새로운 형태의 데이터를 만들어내기위해.
→ 연산자를 이용함.
사원의 연봉을 알아보기 예제)
-- 연산자
-- 산술연산자 : +, -, /, *
-- null 값은 연산이 불가하다, 연산을 하면 모든 결과가 null이 되어버림.
-- 연산이 불가한 null 데이터를 연산이 가능하도록 임시로 변경할 수 있다.
-- nvl() : null 값을 원하는 값으로 변경해준다.
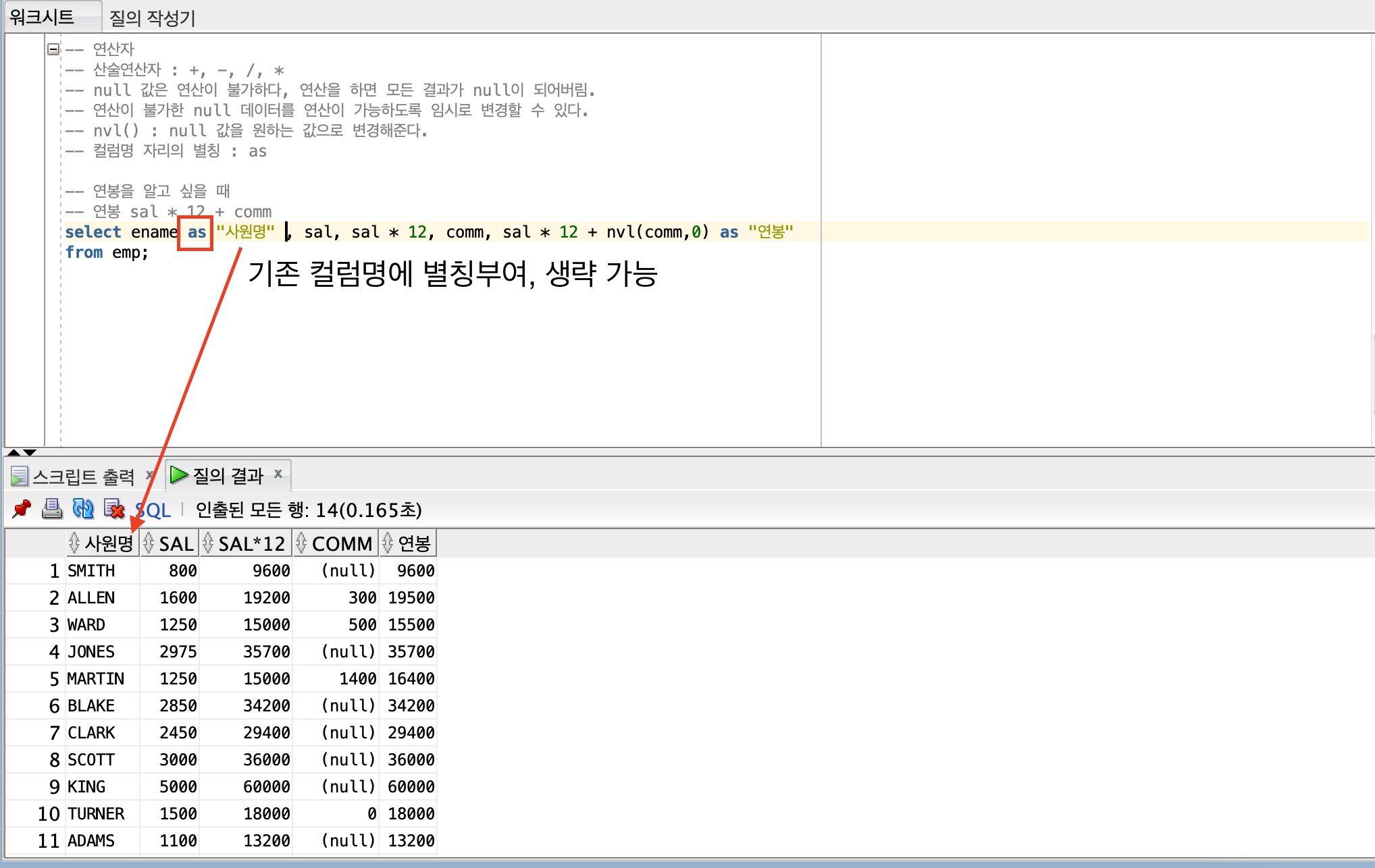
-- 기존 컬럼명 별칭 부여 : as (생략가능)
-- 연봉을 알고 싶을 때
-- 연봉 sal * 12 + comm
select ename "사원명" , sal, sal * 12, comm, sal * 12 + nvl(comm,0) as "연봉"
from emp;
nvl(comm,0) → comm 에서 나오는 null 값을 임시적으로 0으로 변경해서 계산해라
결과 :
|| 와 distinct
-- || 를 이용한 합치기
select ename || ' is a ' || job
from emp;
-- 중복제거
select distinct job
from emp;
조건절
-- 조건절
-- where 조건식 (컬럼명 = 값)
-- 비교연산자 ( =, !=, <, >, <=, >= )
-- 숫자
-- 문자 : 홑따옴표 사용, 대소문자 구분
-- 날짜 : 홑따옴표, 날짜형식(년, 일, 월)
-- 숫자
select *
from emp
where sal >= 3000;
select *
from emp
where deptno = 10;
-- 문자
select *
from emp
where ename = 'SCOTT'; -- 대소문자 구분
select *
from emp
where job = 'SALESMAN';
-- 날짜 (구분자는 생략가능)
select *
from emp
where hiredate < '19820101';
-- where hiredate < '1982/01/01';
SQL 문자를 쓸 때는 ‘ ‘ ( “는 쓰지않는다)
논리연산자
-- 논리연산자
-- and, or, not
select *
from emp
where deptno = 10
and job = 'MANAGER';
select *
from emp
where deptno = 10
or job = 'MANAGER';
select *
from emp
where not deptno = 10;
select *
from emp
where deptno <> 10; -- != , <> 같지 않다는 뜻의 연산자
select *
from emp
where not (sal >= 2000 and sal <= 3000);
select *
from emp
-- where sal >= 2000 and sal <= 3000;
where not (sal < 2000 or sal > 3000);
-- and 와 or 를 간단하게 쓸 수 있는 연산자
-- between 값1 and 값2
select *
from emp
where sal between 2000 and 3000;
select *
from emp
where sal not between 2000 and 3000;
-- in()
select *
from emp
where comm = 300 or comm = 500 or comm = 1400;
select *
from emp
where comm in(300, 500, 1400);
select *
from emp
where comm not in(300, 500, 1400);
like 연산자와 와일드카드
-- like 연산자와 와일드카드
-- _ : 하나의 문자가 반드시 있어야 한다.
-- % : %가 오는 자리에는 값이 없어도 되고 하나 이상 여러 글자가 있어도 된다.
-- 값의 일부를 가지고 조회하는 방식
-- like 만 쓰면 의미가 없어 _, % 와 같이 쓴다.
select *
from emp
where ename like 'F%';
select *
from emp
where ename like '%R';
select *반
from emp
where ename like '%A%';
select *
from emp
where ename like '_L%';
-- like의 부정
select *
from emp
where ename not like '_L%';
null 데이터 조건절에서 조회
-- null 데이터 조건절에서 조회
-- is null
-- is not null
-- nvl(null, 바꾸고 싶은 값) : 값의 타입이 일치해야 한다
select *
from emp
where comm is null;
select sal, sal * 12 + nvl(comm,0)
from emp
where comm is not null;
정렬(오름, 내림)
-- 정렬(오름, 내림)
-- order by 컬럼명 asc 오름 / desc 내림
-- asc은 생략가능 (기본값)
select *
from emp
order by sal asc;
select *
from emp
order by sal desc;
select *
from emp
order by hiredate desc;
select *
from emp
order by sal desc, ename asc; -- sal desc 기준으로 ename asc 정렬
-- 부서로 정렬하고 이름으로 정렬
select *
from emp
order by deptno;
select *
from emp
order by ename;
오늘 UI구현시험은 말아먹었다. 왜 피그마도 못하는 걸까..
진짜 열심히 만들었는데 프로토타입이 실행이 안된다..
암튼 그냥 한숨쉬고 있는데 단위평가 점수가 28점이라 보니까 아직 체점 중이어서 그렇다고, ㅋㅋ 근데 그와중에 인터넷에 치면 다 나오는 서술형을 하나 틀렸다는 걸 알게 되었다.
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
public class TcpIpMultichatServer {
// 사용자의 이름과 클라이언트와 연결된 소켁 정보 관리 HashMap 사용
HashMap clients;
TcpIpMultichatServer() {
clients = new HashMap();
// HashMap에 동기화를 걸어 스레드가 동시에 접근하지 못하도록 한다
// 기존 HashMap을 동기화처리가 안되어 있음. 필요할 때 직접 동기화 처리를 하도록
Collections.synchronizedMap(clients); // 컬렉션의 동기화
}
// 서브소켓 생성, 클라이언트와 연결
public void start() {
ServerSocket serverSocket = null;
Socket socket = null;
try {
serverSocket = new ServerSocket(7777);
System.out.println("서버가 시작되었습니다.");
// 서버는 죽으면 안된다
// 무한하게 클라이언트의 요청을 받기
while (true) {
socket = serverSocket.accept();
System.out.println("[" + socket.getInetAddress() + ":" + socket.getPort() + "]" + "에서 접속했습니다.");
// 현재 접속된 클라이언트의 정보를 넘긴다
ServerReceiver thread = new ServerReceiver(socket);
thread.start();
}
// 클라이언트의 정보가 들어오면 HashMap에 저장해야 한다
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// 소켓을 여러 개 만들 수 있다면 멀티 가능
// 콜렉션(ArrayList)을 이용해 소켓정보를 저장
// command + option + up / down 한줄 복사
// command + F11 샐행
new TcpIpMultichatServer().start();
}
class ServerReceiver extends Thread {
Socket socket;
DataInputStream in;
DataOutputStream out;
public ServerReceiver(Socket socket) {
this.socket = socket;
try {
in = new DataInputStream(socket.getInputStream());
out = new DataOutputStream(socket.getOutputStream());
} catch (IOException e) {
}
}
void sendToAll(String msg) { // 현재 접속한 모든 클라이언트에게 메세지 전달
Iterator it = clients.keySet().iterator();
while (it.hasNext()) {
try {
DataOutputStream out = (DataOutputStream) clients.get(it.next());
out.writeUTF(msg);
} catch (Exception e) {
}
}
}
// 데이터를 받아서 연결된 클라이언트에게 보내는 작업
// 클라이언트의 이름을 받아 그 사람이 접속했다는 것을 이름으로 알려주기
@Override
public void run() {
String name = "";
try {
name = in.readUTF();
sendToAll("#" + name + "님이 들어오셨습니다.");
clients.put(name, out);
System.out.println("현재 서버접속자 수는 " + clients.size() + "입니다.");
while (in != null) {
sendToAll(in.readUTF());
}
} catch (IOException e) {
// 대화하다 클라이언트가 나갈 때
// 클라이언트 삭제
} finally {
sendToAll("#" + name + "님이 나가셨습니다.");
clients.remove(name);
System.out.println("[" + socket.getInetAddress() + ":" + socket.getPort() + "]" + "에서 접속을 종료하였습니다.");
System.out.println("현재 서버접속자 수는 " + clients.size() + "입니다.");
}
}
}
}
클라이언트 코드 :
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.Socket;
import java.net.UnknownHostException;
import java.util.Scanner;
public class TcpIpMultichatClient {
public static void main(String[] args) {
// 접속할 서버에 대한 정보 세팅
// 서버의 정보를 문자열로 처리
String serverIP = "192.168.105.80";
Scanner sc = new Scanner(System.in);
System.out.println("대화명 입력 >>");
String name = sc.next();
try {
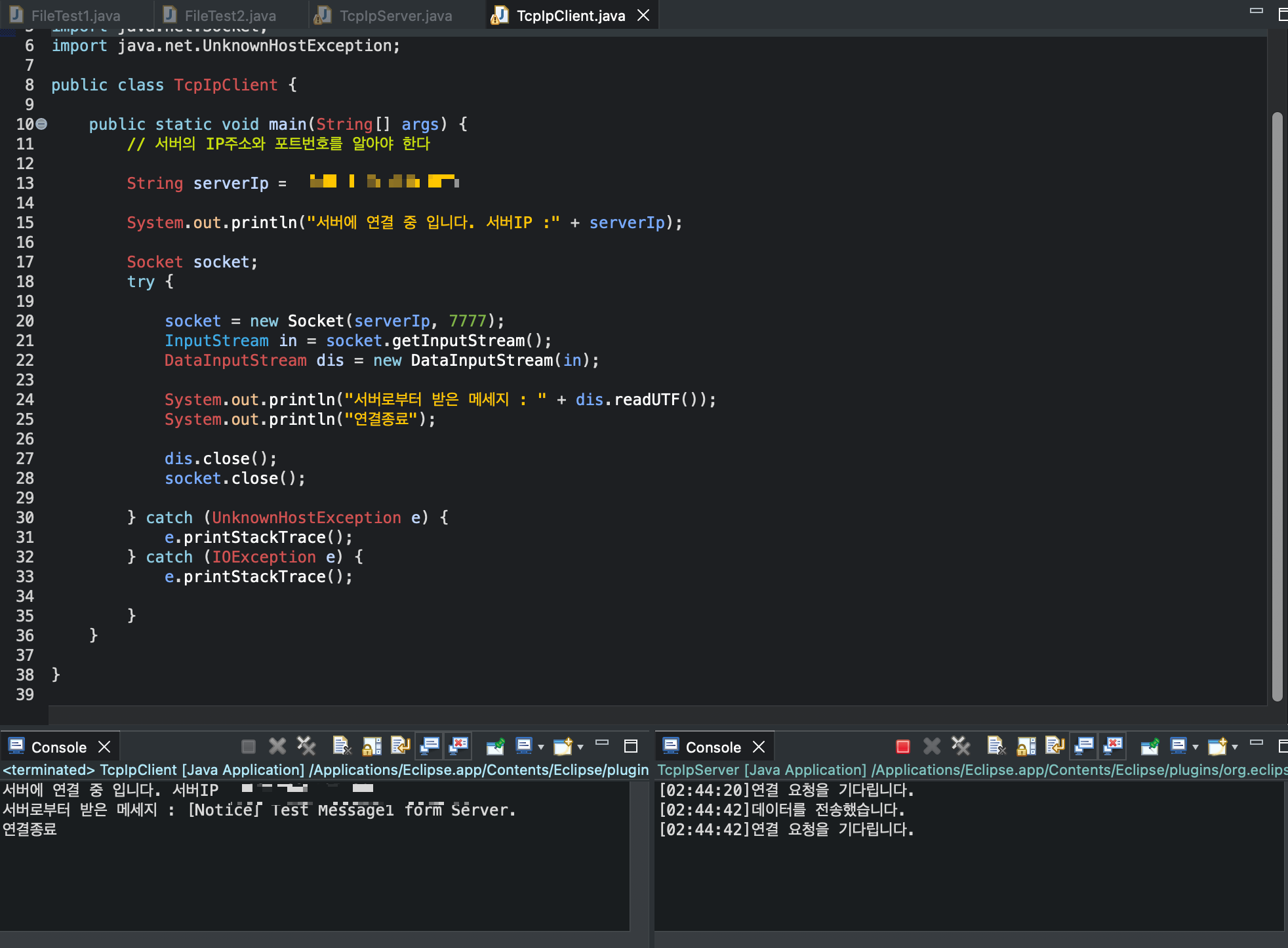
Socket socket = new Socket(serverIP, 7777);
System.out.println("서버에 연결되었습니다");
// 메세지 전송
Thread sender = new Thread(new ClientSender(socket, name));
// 메세지 수신
Thread receiver = new Thread(new clientReceiver(socket));
sender.start();
receiver.start();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} // main end
static class ClientSender extends Thread {
Socket socket;
DataOutputStream out;
String name;
public ClientSender(Socket socket, String name) {
this.socket = socket;
this.name = name;
try {
out = new DataOutputStream(socket.getOutputStream());
} catch (Exception e) {
}
}
// 문자메세지 입력
@Override
public void run() {
Scanner sc = new Scanner(System.in);
try {
if (out != null) {
out.writeUTF(name);
}
while (out != null) {
out.writeUTF("[" + name + "]" + sc.nextLine());
}
} catch (Exception e) {
}
}
}
// 문자메세지 받기
static class clientReceiver extends Thread {
Socket socket;
DataInputStream in;
String name;
public clientReceiver(Socket socket) {
this.socket = socket;
try {
in = new DataInputStream(socket.getInputStream());
} catch (Exception e) {
}
}
@Override
public void run() {
while (in != null) {
try {
System.out.println(in.readUTF());
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
read(), read(char[] c), read(char[] c, int off, int len)
// Writer
writer(int c), writer(char[] c), writer(char[] c, int off, int len)
writer(String srt), writer(String str, int off, int len)
// 문자 기반 보조 스트림
BufferedReader, BufferWriter
FileReader, Filewriter 로 문자열 읽어오기
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
public class FileReaderTest1 {
public static void main(String[] args) {
// FileReader, Filewriter
try {
FileInputStream fis = new FileInputStream("test.txt");
FileReader fr = new FileReader("test.txt");
int data = 0;
while ((data = fis.read()) != -1) {
System.out.print((char) data);
}
System.out.println();
fis.close();
while ((data = fr.read()) != -1) {
System.out.print((char) data);
}
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
파일 내용 :
Hello, 안녕하세요?
출력 :
Hello, ìë íì¸ì? // 바이트 기반으로 읽어오면 한글 깨짐이 생긴다
Hello, 안녕하세요? // 문자 기반으로 읽어오면 한글 깨짐이 생기지 않는다
문자 기반 보조 스트림으로 파일 읽어오기
BufferedReader, BufferWriter
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class BufferedReaderTest {
public static void main(String[] args) {
try {
FileReader fr = new FileReader("src/BufferedReaderTest.java");
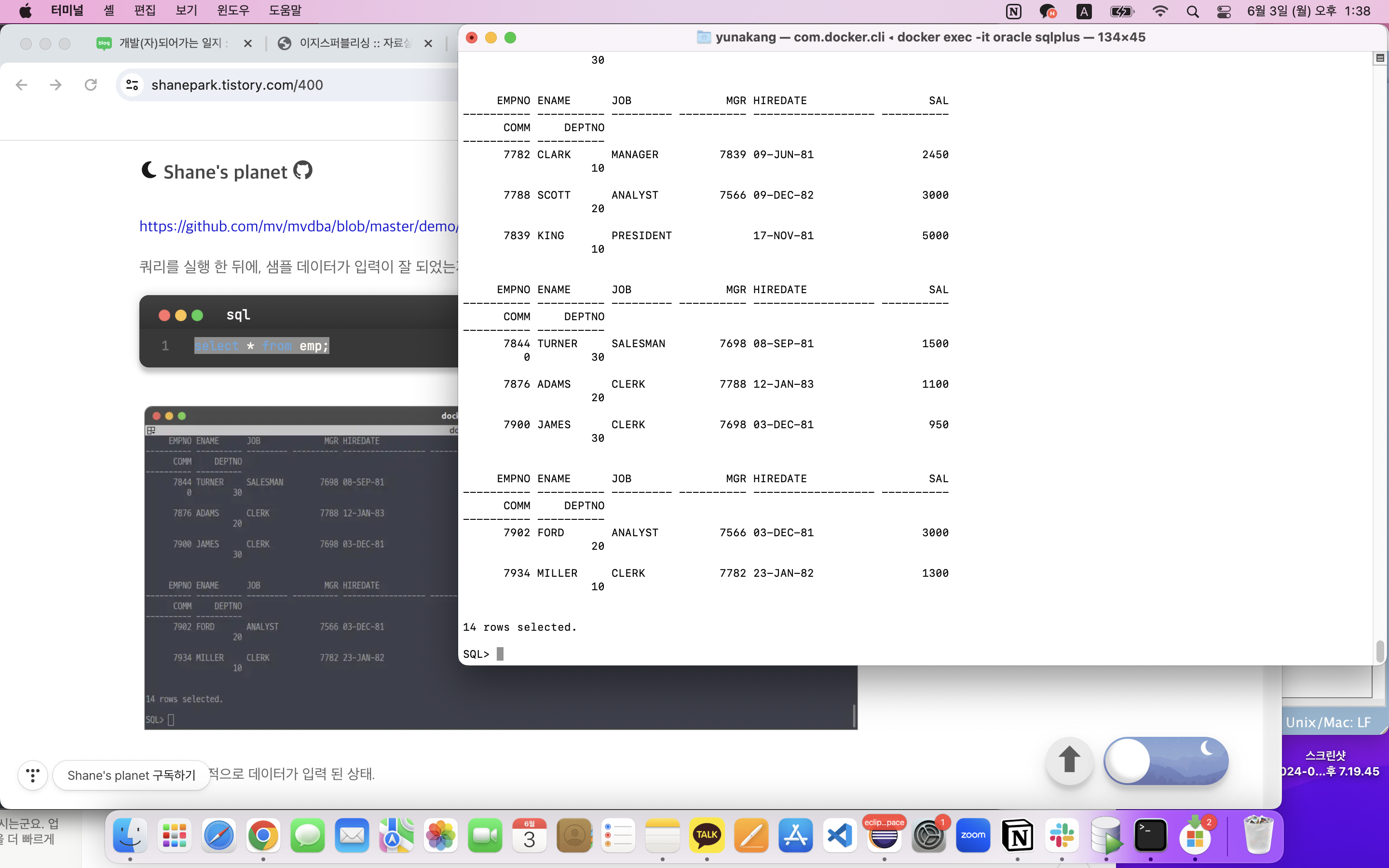
BufferedReader br = new BufferedReader(fr); // 보조스트림(메인스트림)
String line = "";
// 보조스트림을 사용해 문자열을 라인단위로 읽어올 수 있다.
// 더 이상 읽을 값이 없으면 null을 반환한다.
for (int i = 1; (line = br.readLine()) != null; i++) {
System.out.println(line);
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
출력 :
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class BufferedReaderTest {
public static void main(String[] args) {
try {
FileReader fr = new FileReader("src/BufferedReaderTest.java");
BufferedReader br = new BufferedReader(fr); // 보조스트림(메인스트림)
String line = "";
// 보조스트림을 사용해 문자열을 라인단위로 읽어올 수 있다.
// 더 이상 읽을 값이 없으면 null을 반환한다.
for (int i = 1; (line = br.readLine()) != null; i++) {
System.out.println(line);
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
BufferedReader의 line으로 파일 복사하기
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class BufferedReaderTest {
public static void main(String[] args) {
try {
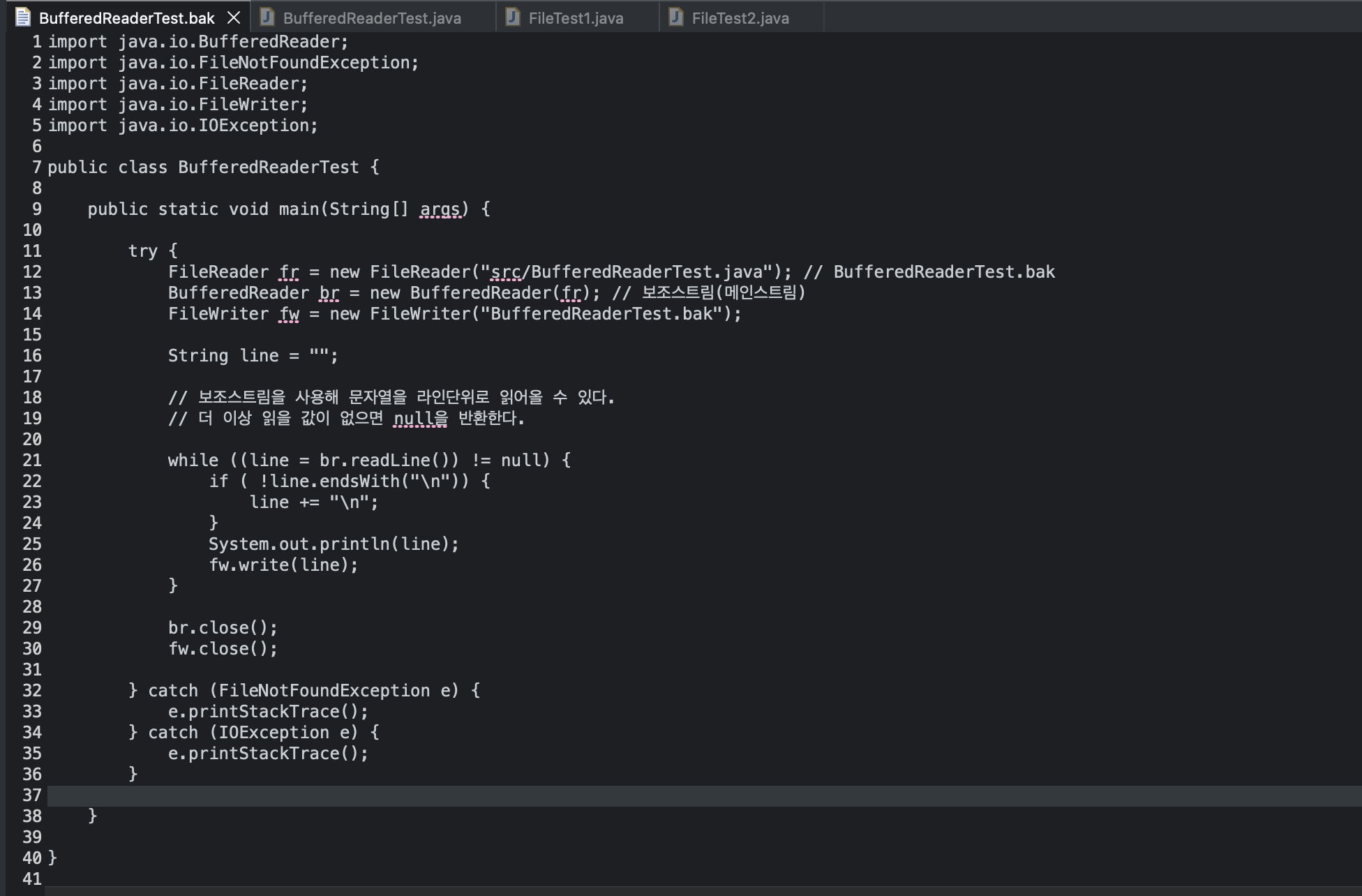
FileReader fr = new FileReader("src/BufferedReaderTest.java"); // BufferedReaderTest.bak
BufferedReader br = new BufferedReader(fr); // 보조스트림(메인스트림)
FileWriter fw = new FileWriter("BufferedReaderTest.bak");
String line = "";
// 보조스트림을 사용해 문자열을 라인단위로 읽어올 수 있다.
// 더 이상 읽을 값이 없으면 null을 반환한다.
while ((line = br.readLine()) != null) {
if ( !line.endsWith("\n")) {
line += "\n";
}
System.out.println(line);
fw.write(line);
}
br.close();
fw.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
결과 :
if ( !line.endsWith("\n")) {
line += "\n";
}
위 구문을 써야하는 이유 :
BufferedReader.readLine() 메서드는 **줄 끝 문자(\\n 또는 \\r\\n)**를 만날 때까지 문자열을 읽어 하나의 문자열로 반환
때문에 저 구문 없이 실행하면 ‘BufferedReaderTest.bak’ 파일에는 다 한줄로 코드가 복사된다.
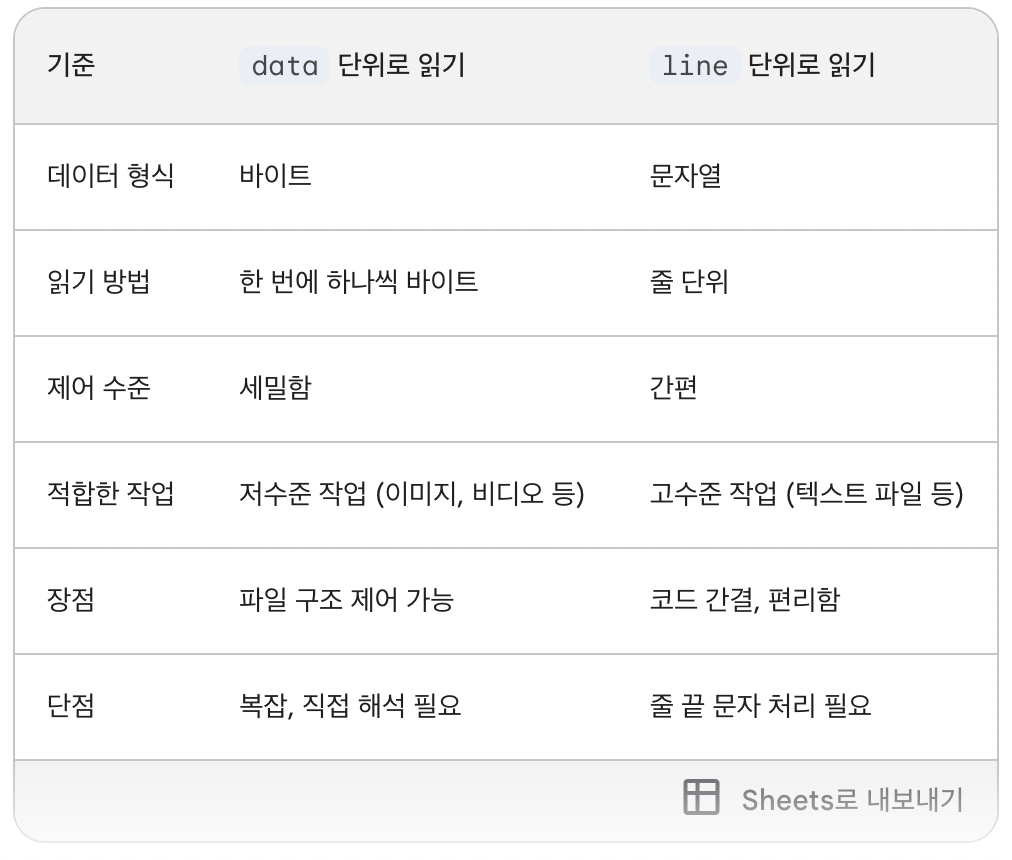
line 과 data 로 파일을 읽어오는 방법 비교
출저 : 구글 gemini
✨ 파일클래스
파일과 관련된 정보, 작업을 처리
출저 : 자바 API
맥에서 파일경로 찾기 : command + i
파일다루기
import java.io.File;
import java.io.IOException;
public class FileTest1 {
public static void main(String[] args) {
// File
// 자바에서 제공하는 라이브러리
// 파일 또는 디렉토리 정보를 다루는 기능
// 생성자에 정의하는파일 정보가 없어도 오류가 발생하지 않는다.
// 파일이 존재하지 않아도 결과가 나온다.
// File f = new File("/Users/yunakang/eclipse-workspace/IOStreamProject0530/src/FileTest1.java");
// File f = new File("/Users/yunakang/eclipse-workspace/IOStreamProject0530/src","/FileTest1.java");
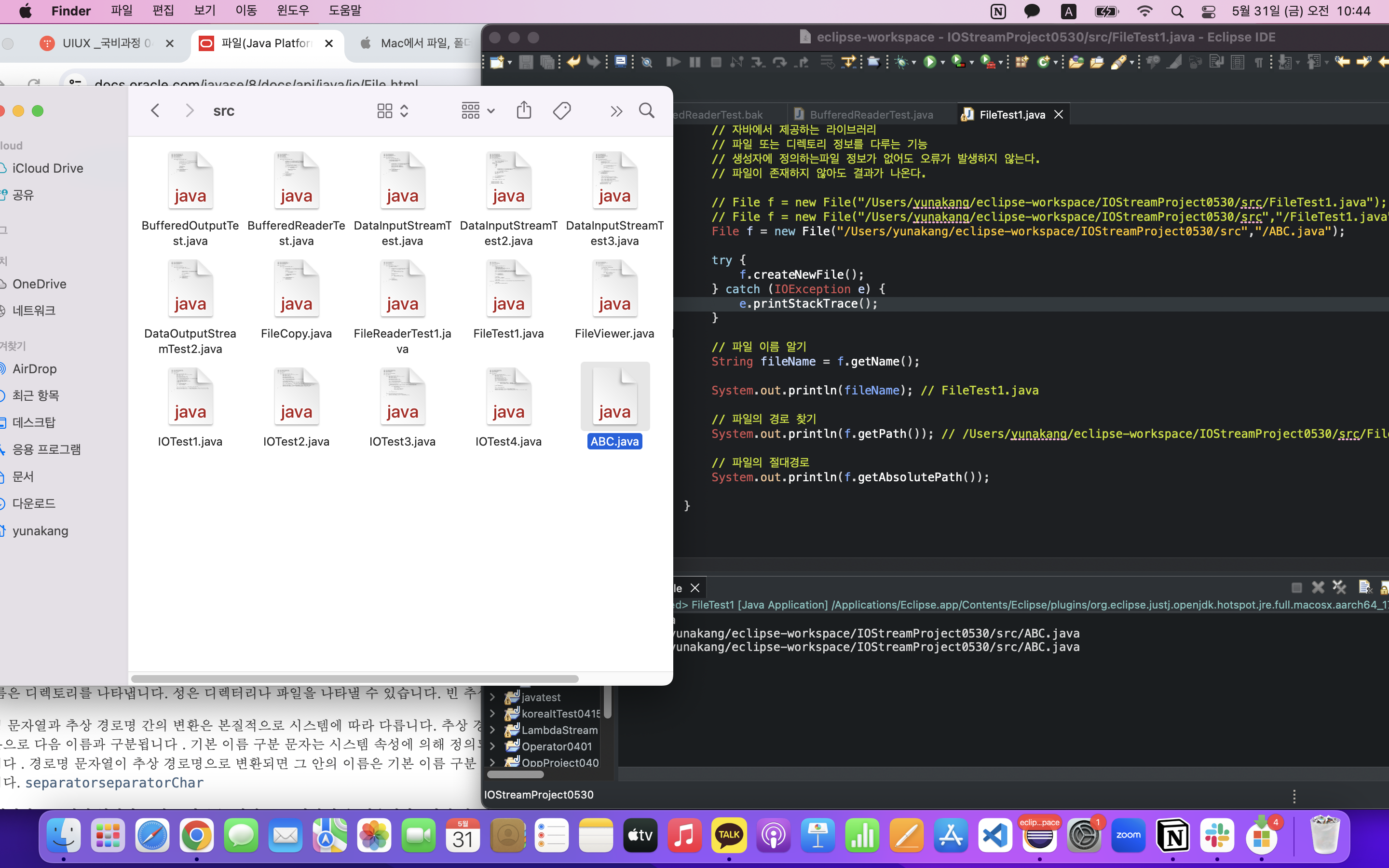
File f = new File("/Users/yunakang/eclipse-workspace/IOStreamProject0530/src","/ABC.txt");
// 파일 새로 만들기
try {
f.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
// 파일 이름 알기
String fileName = f.getName();
System.out.println(fileName); // FileTest1.java
// 파일의 경로 찾기
System.out.println(f.getPath()); // /Users/yunakang/eclipse-workspace/IOStreamProject0530/src/FileTest1.java
// 파일의 절대경로
System.out.println(f.getAbsolutePath());
// 파일 이름을 바꾸며 똑같은 내용을 가진 파일을 새로 생성 (복사의 개념)
File newFile = new File("/Users/yunakang/eclipse-workspace/IOStreamProject0530/src","/rename.txt");
f.renameTo(newFile);
// 필요없는 기존 파일 지우기
f.delete();
System.out.println(newFile.getName());
}
}
결과 :
파일이 새로 생겼다. (자바파일로 잘못만들어서 txt파일로 고쳐줬다.)
그 후 renameTo()를 이용해 파일의 이름을 바꿔 새 파일을 만들고 기존의 파일은 삭제하는 작업까지 해보았다.
파일의 목록 읽어오기
import java.io.File;
public class FileTest2 {
public static void main(String[] args) {
// 파일의 목록을 읽어오는 프로그래밍
// 목록을 읽어오기 위해서 배열로 가지고 와서 저장
File f = new File("/Users/yunakang/eclipse-workspace/IOStreamProject0530");
// 파일이 없을 때 체크
if (!f.exists() || !f.isDirectory()) {
System.out.println("파일 정보가 존재하지 않습니다");
// 프로그램 강제 종료
System.exit(0);
}
File[] files = f.listFiles();
for (int i = 0; i < files.length; i++) {
String fileName = files[i].getName();
// 파일인지 디렉토리인지 구분, 파일이면 괄호 안에 이름
System.out.println(files[i].isDirectory() ? "[" + fileName + "]" : fileName) ;
}
}
}