힘들게 만든 OE계정에서,,
나이 구하기
+ 연령대 구하기
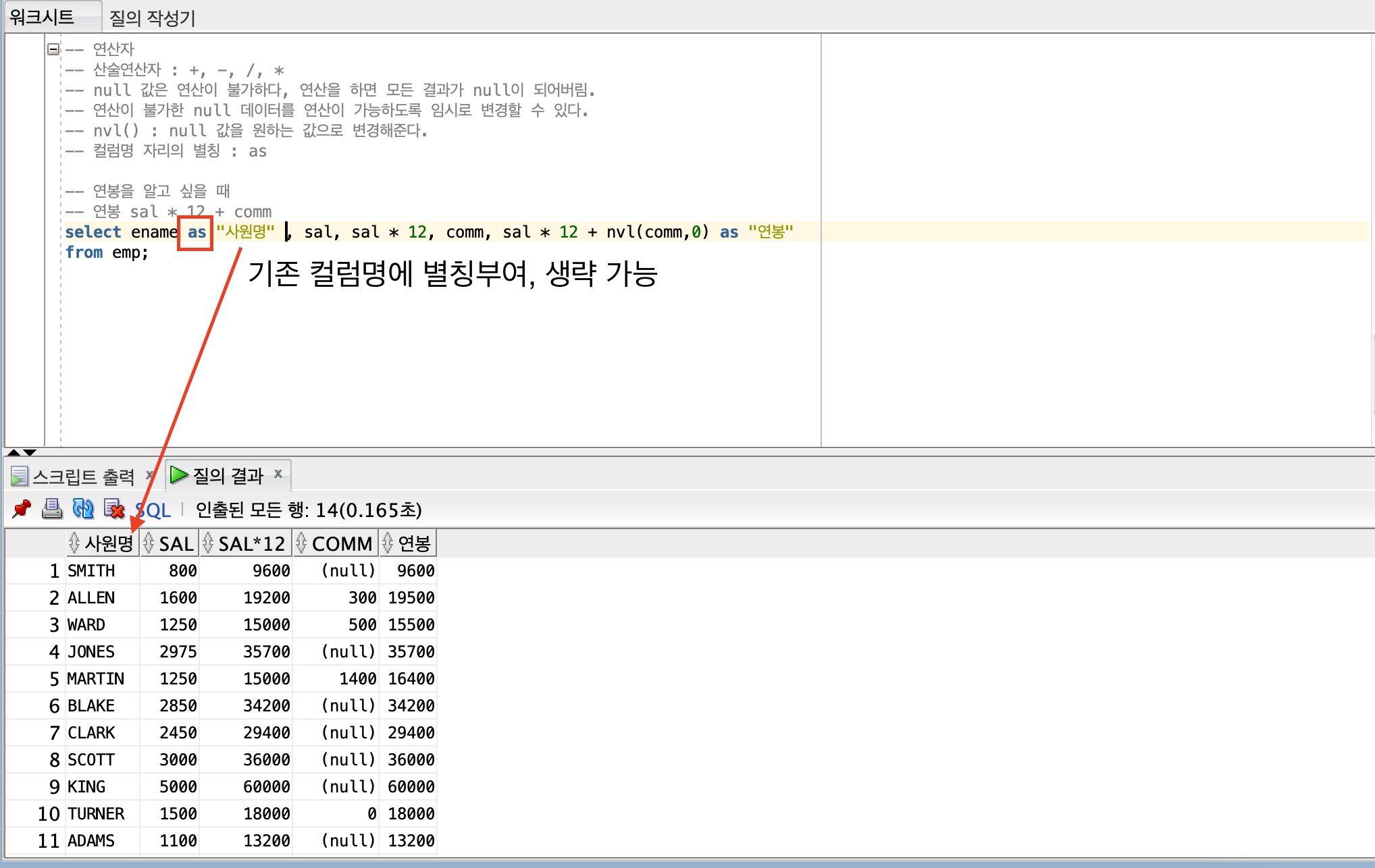
select date_of_birth,to_char(date_of_birth,'YYYY/MM/DD') as birth,
trunc((sysdate - date_of_birth) / 365) as age,
case
when trunc((sysdate - date_of_birth) / 365) >= 70 and trunc((sysdate - date_of_birth) / 365) < 80 then '70대'
when trunc((sysdate - date_of_birth) / 365) >= 60 and trunc((sysdate - date_of_birth) / 365) < 70 then '60대'
when trunc((sysdate - date_of_birth) / 365) >= 50 and trunc((sysdate - date_of_birth) / 365) < 60 then '50대'
when trunc((sysdate - date_of_birth) / 365) >= 40 and trunc((sysdate - date_of_birth) / 365) < 50 then '40대'
when trunc((sysdate - date_of_birth) / 365) >= 30 and trunc((sysdate - date_of_birth) / 365) < 40 then '30대'
when trunc((sysdate - date_of_birth) / 365) >= 20 and trunc((sysdate - date_of_birth) / 365) < 30 then '20대'
when trunc((sysdate - date_of_birth) / 365) >= 10 and trunc((sysdate - date_of_birth) / 365) < 20 then '10대'
else '기타'
end as Generation
from customers;
---------------------------------------------------------------------------------------------------
위 구문을 식으로 바꿔보았다 (아래)
select date_of_birth,to_char(date_of_birth,'YYYY/MM/DD') as birth,
trunc((sysdate - date_of_birth) / 365) as age,
case
when sysdate-date_of_birth >= 0 then floor(floor((sysdate-date_of_birth)/365)/10)*10 || '대'
else '기타'
end as Generation
from customers;조건이 반복되면 간략하게 만들어서 사용할 생각을 하자
다시 scott 계정으로 돌아왔다
단일행 함수 → input과 output의 수가 같음.
다중행 함수 → input이 여러개여도 output은 하나
-- 단일행 합수 : round(), floor()..
-- 다중행 함수 : sum(), avg(), max(), min(), count()..
-- 회사직원들의 급여 합, 평균
-- distinct 중복제거
select sum(sal), sum(distinct sal), avg(distinct sal)
from emp;
select sal
from emp;
-- 전체 사원 14명, 성과금받는 직원 4명, 성과금의 합 2200, 급여가 같은 사원 중복제거
-- 다중행함수는 null 값을 무시한다
select count(*), count(comm), sum(comm), count(distinct sal)
from emp;
select max(sal), min(sal)
from emp;
-- 일반컬럼과 단일행 그룹 함수는 함께 사용할 수 없다.
-- 각 컬럼에 조회된 결과의 개수가 같아야 한다.
select ename, max(sal)
from emp;
-- 일반컬럼과 단일행 그룹 함수는 함께 사용할 수 없다.
select max(sal)
from emp;
-- 추후 해결하는 방법을 배울 예정
group by절
-- group by 기준 컬럼
-- 테이블에 데이터를 논리적으로 묶어서 처리하는 역할
select *
from emp
order by deptno;
-- 부서 별 급여의 합계, 평균
-- group by로 묶이면 그룹의 갯수대로 값이 나온다
-- group by에 사용되는 컬럼은 그룹함수와 함께 사용될 수 있다
select deptno, sum(sal), avg(sal)
from emp
group by deptno;
select *
from emp
order by deptno;
select deptno, job, sum(sal)
from emp
group by deptno, job
order by deptno;
-- having 조건절
-- where 그룹함수를 조건식으로 사용 불가, group by절 보다 먼저 실행된다
select deptno, sum(sal)
from emp
group by deptno
having sum(sal) > 9000;
-- where절과 group by절을 함께 사용한 예제
select deptno, job, avg(sal)
from emp
where sal <= 3000
group by deptno, job
-- having avg(sal) >= 2000; -- 그룹함수를 사용하여 조건식을 구성한다.
having deptno = 10;
문제풀기
-- 문제 풀기
-- 1번
select deptno, trunc(avg(sal)) as AVG_SAL, max(sal) as MAX_SAL, min(sal) as MIN_SAL, count(*) as CNT
from emp
group by deptno;
-- 2번
select job, count(*)
from emp
group by job
having count(*) >= 3;
-- 3번
select to_char(hiredate,'YYYY') as HIRE_YEAR, deptno, count(*) as CNT
from emp
group by to_char(hiredate,'YYYY'), deptno
order by HIRE_YEAR;
group by 절 사용 방법
select
from
where
group by
having
order by -- 가장 마지막에 작성
join
조인
- 두개 이상의 테이블을 사용하여 데이터를 조회하는 것
- 두개의 테이블의 공통컬럼을 사용하여 데이터를 조회
- 하나의 쿼리문으로 데이터 통합 조회
- from절에 두개 이상의 테이블을 사용한다
--종류
-- cross join : 조건없이 양쪽 테이블을 모두 조회
-- equi join : 공통 컬럼에 값을 비교해서 같으면 조회(등가)
-- non equi join : 컬럼의 값을 범위 비교한다
-- self join : 하나의 테이블을 두개의 테이블처럼 사용하여 조회(등가)
-- outer join : 누락된 데이터를 조회(등가)
select *
from emp;
select *
from dept;
-- cross join
select *
from emp, dept;
-- equi join
select ename, sal, emp.deptno, dname, loc
from emp, dept
where emp.deptno = dept.deptno; -- 조인 조건
-- 공통으로 가지고 있는 컬럼이 아니라면 생략이 가능하다
-- select emp.ename, emp.sal, emp.deptno, dept.dname, dept.loc
select ename, sal, e.deptno, dname, loc
from emp e, dept d -- 별칭사용 (원래 테이블명 사용불가)
where e.deptno = d.deptno -- 조인 조건
and ename = 'SMITH'; -- 일반 조건
-- non equi join
select *
from emp;
select *
from salgrade;
select ename, sal, grade
from emp e, salgrade s
-- where e.sal >= s.losal and e.sal <= s.hisal; -- 범위 비교
where e.sal between s.losal and s.hisal;
-- slef join
select *
from emp;
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e, emp m -- emp(mgr) = emp(empno)
where e.mgr = m.empno; -- 조인 조건
-- null값 누락
-- outer join
-- 누락되는 null 값도 가지고 온다
-- 조인 조건식의 한쪽 컬럼에 (+)표시를 작성한다 -> 해당 데이터가 없는 쪽에 붙일 것.
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e, emp m -- emp(mgr) = emp(empno)
where e.mgr = m.empno(+); -- 조인 조건
select ename, sal, d.deptno, dname
from emp e,dept d
where e.deptno(+) = d.deptno;
-- 사원이름, 급여, 부서번호, 부서명, 급여등급
select ename, sal, e.deptno, dname, grade
from emp e, dept d, salgrade s
where e.deptno = d.deptno
and e.sal between s.losal and s.hisal;
표준조인방식
-- 표준 조인 방식 (ANSI-JOIN)
-- 위의 조인 방식은 오라클에서 쓸 수있는 조인
-- 이 표준 조인 방식은 어디에서나 사용 가능
-- 호환성을 위해 표준을 쓰는 것을 권고한다
-- 종류
-- cross join
-- inner join(equi join, non equi join, self join)
-- outer join
select *
from emp cross join dept;
-- 조건문 on
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d -- inner 생략 가능
on e.deptno = d.deptno;
-- 일반조건 추가 where
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d -- inner 생략 가능
on e.deptno = d.deptno -- 조인조건
where ename = 'SCOTT'; -- 일반조건
select ename, sal, e.deptno, dname, loc
from emp e inner join dept d
-- on e.deptno = d.deptno
using(deptno); -- 조인 조건 (컬럼명이 동일할 경우)
select ename, sal, grade
from emp e inner join salgrade s
on e.sal between s.losal and s.hisal;
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e inner join emp m
on e.mgr = m.empno;
-- left, right, full을 outer 앞에 붙여줘야한다
select e.ename || '의 매니저는 ' || m.ename || ' 입니다'
from emp e left outer join emp m
on e.mgr = m.empno;
-- 테이블 먼저 나열하고 쓰면 안된다
select ename, sal, e.deptno, dname, grade
from emp e inner join dept d
on e.deptno = d.deptno
inner join salgrade s
on e.sal between s.losal and s.hisal;
서브쿼리문
-- 서브 쿼리문
-- select 문 안에 중첩되는 select 구문
-- 단일행 서브쿼리 : 결과가 하나 (비교연산자)
-- 다중행 서브쿼리 : 결과가 여러 개 (비교연산자 사용 불가), in, any, all
-- select (select)
-- from (select)
-- where (select)
--------------------단일행 서브쿼리--------------------
-- SCOTT 보다 급여를 많이 받는 사람을 알고 싶을 때
select sal
from emp
where ename = 'JONES';
select *
from emp
where sal > (
select sal
from emp
where ename = 'SCOTT'
);
-- 근무지가 뉴욕인 사람들
select *
from emp
where deptno = (
select deptno
from dept
where loc = 'NEW YORK'
);
-- 급여를 가장 많이 받는 사원의 급여와 사원이름
select max(sal)
from emp;
select ename,sal
from emp
where sal = (
select max(sal)
from emp
);
--------------------단일행 서브쿼리--------------------
--------------------다중행 서브쿼리--------------------
-- 급여를 3000 이상 받는 사람들
select ename, sal, deptno
from emp
where deptno in ( -- or 조건과 동일
select distinct deptno
from emp
where sal >= 3000
);
-- 30번 부서에서 근무하는 사람들의 급여 조회, 그 급여보다 많은 급여를 받는 사람 조회
select ename, sal
from emp
where sal > all (
select sal
from emp
where deptno = 30
);
-- any : 값 중에 가장 작은 값보다 큰 값을 가진 사원 조회
-- all : 값 중에 가장 큰 값보다 큰 값을 가진 사원 조회
--------------------다중행 서브쿼리--------------------
✔️ 테이블 만들기
DDL (data definition language)
-- creat : 객체 생성
-- alter : 객체 수정
-- drop : 객체 삭제
-- truncate : 테이블을 초기화
create table 테이블명 (
컬럼명1 타입,
컬럼명2 타입,
컬럼명3 타입,
);
-- 컬럼이름을 만든 후 타입에 사용
-- 숫자 : number(4), number(7,2)
-- 문자 : char(10) : 고정형, varchar2(10) : 가변형
-- 문자를 다룰 때는 가변형을 주로 사용한다
-- 날짜 : date, timestamp'2024_UIUX 국비 TIL' 카테고리의 다른 글
| UIUX _국비과정 0612 [오라클SQL View] (0) | 2024.07.01 |
|---|---|
| UIUX _국비과정 0611 [오라클DB SQL 쿼리문] (0) | 2024.07.01 |
| UIUX _국비과정 0605 [오라클DB SQL 쿼리문] (0) | 2024.06.24 |
| UIUX _국비과정 0604 [오라클DB SQL 쿼리문] (0) | 2024.06.24 |
| UIUX _국비과정 0603 [오라클DB] (0) | 2024.06.24 |